System Architecture
- Elements of Scale: Composing and Scaling Data Platforms
- Please stop calling databases CP or AP
- What we talk about when we talk about distributed systems
- A Comprehensive Guide to Building a Scalable Web App on Amazon Web Services
- Notes on Google's Site Reliability Engineering Book or the book itself
HDD
- Stores data on a series of constantly-spinning magnetic disks, called platters.
- Actuator arm with read/write heads positions the heads over the correct area of the drive to read/write (nanometers above platters).
- The drive may need to read from multiple locations in order to launch a program or load a file, which means it may have to wait for the platters to spin into the proper position multiple times before it can complete the command.
- If a drive is asleep or in a low-power state, it can take several seconds more for the disk to spin up to full power.
- Latency measured in milliseconds.
- SAS – Serial Attached SCSI – faster than HDD but still with a spinning platter.
SSD
- Don't rely on moving parts or spinning disks.
- Data is saved to a pool of NAND flash.
- NAND itself is made up of what are called floating gate transistors. Unlike the transistor designs used in DRAM, which must be refreshed multiple times per second, NAND flash is designed to retain its charge state even when not powered up.
- NAND flash is organized in a grid. The entire grid layout is referred to as a block, while the individual rows that make up the grid are called a page.
- Common page sizes are 2K, 4K, 8K, or 16K, with 128 to 256 pages per block.
- Block size therefore typically varies between 256KB and 4MB.
- Data read/written at the page level (individual rows within the grid).
- Data erased at the block level (requires a high amount of voltage).
- Latency measured in microseconds.
- SSD controllers have caches and a DDR3 memory pool to help with managing the NAND.
RAID
- Redundant Array of Independent Disks
- Performance increase is a function of striping: data is spread across multiple disks to allow reads and writes to use all the disks' IO queues simultaneously.
- Redundancy is gained by creating special stripes that contain parity information, which can be used to recreate any lost data in the event of a hardware failure.
- Hardware RAID – a dedicated hardware controller with a processor dedicated to RAID calculations and processing.
- RAID 0 – Striping – splits blocks of data into as many pieces as disks are in the array, and writes each piece to a separate disk.
- Single disk failure means all data lost.
- Increased in throughput: throughput of one disk * number of disks.
- Total space is sum of all disks.
- Requires min. 2 drives.
- RAID 1 – Mirroring – duplicates data identically on all disks.
- Data preserved until loss of last drive.
- Reads faster or the same, writes slower.
- Total space = size of smallest disk.
- Requires min. 2 drives.
- RAID 10 – combination of RAID 1 and 0 (in that order). Create arrays of RAID 1, and then apply RAID 0 on top of them. Requires min. 4 disks, additional ones need to be added in pairs. A single disk can be lost in each RAID 1 pair. Guaranteed high speed and availability. Total space = 50% of disk capacity.
- RAID 5 – uses a simple XOR operation to calculate parity. Upon single drive failure, the information can be reconstructed from the remaining drives using the XOR operation on the known data. Any single drive of the drives we have can fail (total number of drives >= 2). In case of drive failure the rebuilding process is IO intensive.
- RAID 6 – like RAID 5, but two disks can fail and no data loss.
CAP Theorem
- Shared-data systems can have at most two of the three following properties: Consistency, Availability, and tolerance to network Partitions.
- Consistency
- There must exist a total order on all operations such that each operation looks as if it were completed at a single instant.
- A system is consistent if an update is applied to all relevant nodes at the same logical time.
- Standard database replication is not strongly consistent because special logic must be introduced to handle replication lag.
- Consistency which is both instantaneous and global is impossible.
- Mitigate by trying to push the time resolutions at which the consistency breaks down to a point where we no longer notice it.
- Availability
- Every request received by a non-failing node in the system must result in a response (that contains the results of the requested work).
- Even when severe network failures occur, every request must terminate.
- Partition Tolerance
- When a network is partitioned, all messages sent from nodes in one component of the partition to nodes in another component are lost.
- Any distributed system can experience a network partition.
- For a distributed system to not require partition-tolerance it would have to run on a network which is guaranteed to never drop messages (or even deliver them late) – but such a network doesn't exist!
- If one node is partitioned, then that node is either inconsistent or not available.
- If a system chooses to provide Consistency over Availability in the presence of partitions, it will preserve the guarantees of its atomic reads and writes by refusing to respond to some requests (like refuse writes on all nodes).
- If a system chooses to provide Availability over Consistency in the presence of partitions, it will respond to all requests, potentially returning stale reads and accepting conflicting writes (which can later be resolved with Vector Clocks, last-write wins, etc.).
- Most real-world systems require substantially less in the way of consistency guarantees than they do in the way of availability guarantees.
- Failures of consistency are usually tolerated or even expected, but just about every failure of availability means lost money.
- The choice of availability over consistency is a business choice, not a technical one.
MapReduce
- Programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.
- Map procedure performs filtering and sorting.
- Reduce procedure performs a summary operation.
- Data transferred between map and reduce servers is compressed. Because servers aren't CPU bound it makes sense to spend on data compression and decompression in order to save on bandwidth and I/O.
- Advantages:
- Nice way to partition tasks across lots of machines.
- Handle machine failure.
- Works across different application types. Almost every application has map reduce type operations. You can precompute useful data, find word counts, sort TBs of data, etc.
- Computation can automatically move closer to the IO source.
- Programs can be very small. As little as 20 to 50 lines of code.
For example, create search inverted index:
// Mapper
/*
* Processes a key/value pair to generate a set of intermediate key/value pairs
*
* @param key id of document
* @param value text of page
* @returns pair of word and document id
*/
public Tuple<String, String> map(String key, String value) {
for (String word : tokenize(value))
return new Tuple<>(word, key);
}
// Reducer
/*
* Merges all intermediate values associated with the same intermediate key
*
* @param key word
* @param value list of document ids
* @returns word to document ids pair
*/
public Tuple<String, List<String>> reduce(String key, List<String> value) {
return new Tuple<>(key, value)
}
Distributed Hash Table
- A decentralized distributed system that provides a lookup service similar to a hash table.
- Any participating node can efficiently retrieve the value associated with a given key.
- Responsibility for maintaining the mapping from keys to values is distributed among the nodes, in such a way that a change in the set of participants causes a minimal amount of disruption.
- Example implementations: Google's BigTable, Cassandra, Hazelcast, Aerospike, Riak.
Data Partitioning (Sharding)
- Split data between multiple nodes.
- Data should be well distributed throughout the set of nodes.
- When a node is added or removed from set of nodes the expected fraction of objects that must be moved to a new node is the minimum needed to maintain a balanced load across the nodes.
- System should be aware which node is responsible for a particular data.
- Simple approach to partitioning of
hashCode(key) % nbreaks when we want to add/remove nodes.
Consistent Hashing
- Special kind of hashing such that when a hash table is resized and consistent hashing is used, only
K/nkeys need to be remapped on average, whereKis number of keys andnis number of buckets. - In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped.
- Originated as a way of distributing requests among a changing population of Web servers.
- Consistent hashing maps objects to the same cache machine, as long as possible.
- When a cache machine is added, it takes its share of objects from all the other cache machines and when it is removed, its objects are shared between the remaining machines.
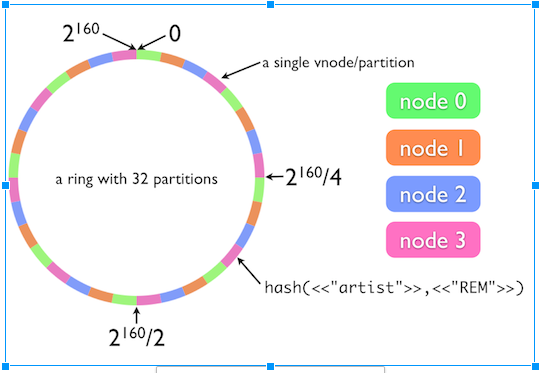
- Consistent hashing is based on mapping each object to a point on the edge of a circle (or equivalently, mapping each object to a real angle). The system maps each available machine (or other storage bucket) to many pseudo-randomly distributed points on the edge of the same circle.
- Apache Cassandra, for example, uses consistent hashing for data partitioning in the cluster.
- An alternative is Rendezvous Hashing.
(source)
Distributed System Consensus
- A fundamental problem in distributed computing is to achieve overall system reliability in the presence of a number of faulty processes.
- Often requires processes to agree on some data value that is needed during computation, e.g., whether to commit a transaction to a database, agreeing on the identity of a leader, state machine replication, and atomic broadcasts.
- Example of algorithms:
- Paxos
- Raft
Resiliency Concepts (Advanced)
- Controlled Delay
- Limit the size of a server's request queue without impacting reliability during normal operations.
- Sets short timeouts, preventing long queues from building up.
- If the queue has not been empty for the last
Nms, then the amount of time spent in the queue is limited toMmilliseconds. If the service has been able to empty the queue within the lastNmilliseconds, then the time spent in the queue is limited toNmilliseconds. - Prevents a standing queue (because the
lastEmptyTimewill be in the distant past, causing anM-ms queuing timeout) while allowing short bursts of queuing for reliability purposes. - Values of
5msforMand100msforNtend to work well across a wide set of use cases.
- Adaptive LIFO
- During normal operating conditions, requests are processed in FIFO order, but when a queue is starting to form, the server switches to LIFO mode.
- Places new requests at the front of the queue, maximizing the chance that they will meet the deadline set by Controlled Delay.
- Backup requests
- Initiate a second ("backup") request to a different server
Nms after the first request was made, if it still hasn't returned. - Dramatic improvement for high percentiles.
- Example flow:
- Send request to first replica.
- Wait 2 ms, and send to second replica.
- Cancel request on other replica when starting to read second request's response.
- Initiate a second ("backup") request to a different server
System Design Question Concepts
- Amount of data (disk)
- RAID configuration
- Amount of RAM – does everything need to be in RAM? (a lot of times – yes)
- Requests/sec
- Request time
- Data transfer rates
- Network requests in single data center
- Geographically separated locations
- Operations should never be more than
nlogn, preferablyn - Sharding/Partitioning (by user/date/content-type/alphabetically) – how do we rebalance?
- Frontend/backend
- Backups? Backup a single user on how many servers?
- Many requests for the same data/lots of updates – all in cache
- Distribute so that the network is negligible
- Parallelizing network requests
- Fan-out (scatter and gather)
- Caching
- Load-balancing
- High availability
- MapReduce
- CDN
- Queues
- Timeouts
- Fail fast
- Circuit breakers
- Throttling
- Consistent hashing for sharding/partitioning
- Compression
- Possible to work harder on writes in order to make reads easier
Platform Needs
- Monitoring (app, resp. time, throughput, OS level, errors)
- Alerting
- Metrics
- Distributed tracing + logging
- Datastores
- Caching
- Queues
- Service discovery
- Configuration
- Debugging, profiling
- ALM and deployment
- Auto scaling
- Load balancing, traffic splitting/control
- KPIs and actions based on them
- Deployment (blue-green), rollback, canary/testbed
Membership Protocols (Advanced)
Summary mainly based on this slide deck and the SWIM paper.
- Determining who are the live peers out of a dynamic group of members.
- Communicating over a network, assuming: packet loss, partitions.
- Useful for discovery in distributed systems.
- Protocols measured by:
- Completeness (do all non-faulty members eventually detect a faulty node)
- Speed of failure detection (time from failure until any node detects the failure)
- Accuracy (rate of false positives)
- Network load
Heartbeating
- Every interval
T, notify peers of liveness. - If no update received from peer
PafterT * limit, mark as dead. - Provides membership + failure detection.
- Broadcast a liveness message on every interval.
- Can be implemented with IP broadcast/multicast (generally disabled) or gossip.
- Network load is
O(n^2)messages on each interval – becomes a bottleneck for large clusters.
SWIM
- Scalable Weakly-Consistent Infection-Style Process Group Membership Protocol.
- Failure detection done by randomly pinging a single peer every interval and marking failed nodes.
- To improve accuracy, before marking a node as failed try indirect ping.
- Indirect ping is asking a set of
Krandom peers to ping the failing candidate. This improves accuracy by attempting other network routes and reduce chance of packet loss. - Network load is
O(n), making is feasible for large clusters. - State updates on membership (joining/leaving the cluster) is achieved by piggybacking on the ping messages for gossip (infection/epidemic).
- Each ping/ack message sent between random nodes adds information about new and left/failed nodes.
- Because pings are sent randomly, nodes will learn about new/failing nodes at different times => eventually (weakly) consistent.
- Ping + piggybacking state updates = membership protocol.